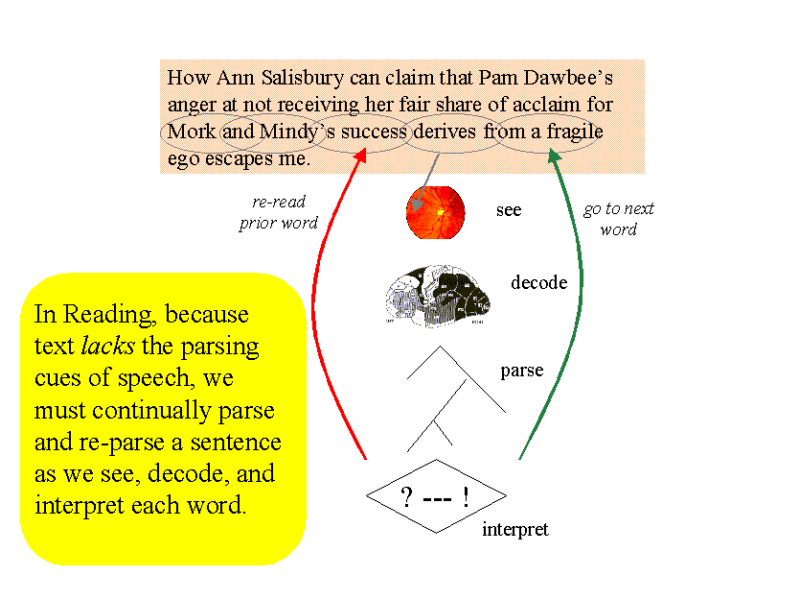
As we serially read one word after the other in conventional text, we have to build up the parsing structure one word at a time -- and we don't have the additional cues to syntactic structure that a listener does. Often we have to re-read words, because we had misinterpreted the syntax of the word the first time.
Return to ClipRead SBIR Project homepage